CPython的内存概念栈、堆和引用
Python的实现版本有很多,例如Jython底层就是JVM,IronPython的底层是.Net,它们的内存管理千差万别取决于底层的运行时系统。在CPython实现中,堆和栈有各自的职责。
C语言
堆(heap)和栈(stack)原本是两种不同的数据结构,在C语言内存表述中,代表着用这两种数据结构管理的两种内存块。
堆由整个系统共享,各个进程拥有同一个堆。 栈由每个进程自行管理,也就是每个进程的栈是独立的,互不相关。
具体区别如下:
- 栈上的内存由系统自动管理分配,用于存储局部变量。 堆中的内存由编程人员主动申请,在C语言中申请内存的函数为malloc, 使用后需要编程人员自行调用free函数释放。
- 从分配释放及访问速度上,栈内存的存取,申请释放速度要高于堆内存。
- 栈内存相对于堆内存要小的多,所以在编程的时候,一般不建议使用占空间过大的局部变量。
- 堆中所有数据均由编程人员申请使用。 栈中除了存放函数中可见的局部变量外,还有各种系统环境数据。
python语言
堆: 主要负责存储CPython运行时的所有对象实体(也就是Python对象的所有属性数据),例如:smt='Hello Word'这个字符串对象PyASCIIObject,n=23这是一个整数PyLongObject,它们都是Python对象,赋值符号=右边的数据值,CPython会将其存储到堆内存中。
栈: 在CPython的语义中,又叫数据栈或值栈,它主要负责保存对堆中Python对象的引用,例如:当CPython在执行smt='Hello Word'这个简单的Python语句,CPython会将'Hello Word'这个字符串实体所处的内存地址压入栈(对于Python语义级别理解,就是对"Hello Word"的引用),而不是将'Hello Word'这个字符串值压入栈。
smt='Hello Word'这些简单的Python赋值语句,你不能单纯地认为将'Hello World'赋值给变量smt,这是大错特错的。
赋值符号右边的是Python对象实体(从C实现的理解,就是构成该PyObject子类对象的属性值,这些值有具体的字面量值表示),并且CPython会为该Python对象在堆中分配内存并且存储它。
而变量smt仅持有该Python对象实体的引用(从C实现的理解,就是该PyObject对象的内存地址),而不是实际的Python对象。
s1变量持有Python对象'Hello world'的引用,对于CPython虚拟机来说,就是在执行s1='Hello Word',将它的内存地址0x71334推入数据栈,那么当CPython碰到同样的语句s2='Hello Word',明显是指向同一个Python对象,那么变量s2和s1一样,它自然持有是'Hello Word'的引用,即s2实质上拥有的'Hello Word'的堆中的地址。
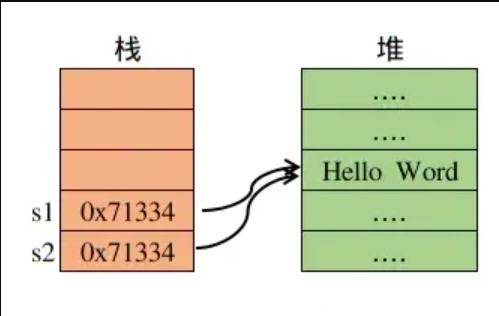
对于其他简易的数据类型,也是如出一辙的。那么现在给Python引用我们可以下一个定义。
Python对象的引用:就是Python变量持有Python对象在堆内存中的内存地址。
我们可以通过python的内置id函数或者关键字is 来判断两个变量是否对同一个对象的引用。
In [1]: s1 = 'hello world'
In [2]: s2 = 'hello world'
In [3]: id(s1)
Out[3]: 4472932144
In [4]: id(s2)
Out[4]: 4472034928
在Python中有两种类型的对象:可变对象和不可变对象。
可变对象: 比较典型的就是list,一个列表作为一个对象存储在堆内存中,如果我们要更改该列表的某些元素,它将仍然是内存中的同一个列表对象。
In [5]: alist = [1, 2, 3]
In [6]: [id(x) for x in alist]
Out[6]: [4439298464, 4439298496, 4439298528]
In [7]: id(alist)
Out[7]: 4474113152
In [8]: alist[1]= 22
In [9]: [id(x) for x in alist]
Out[9]: [4439298464, 4439299136, 4439298528]
In [10]: id(alist)
Out[10]: 4474113152
In [11]: id(22)
Out[11]: 4439299136
In [12]: id(1)
Out[12]: 4439298464
在列表alist中,通过列表表达式打印出列表每个对象元素的内存地址,以及列表对象alist本身的内存地址,然后在修改列表元素后,再次打印列表对象中的各个对象元素的内存地址,以及alist本身的内存地址。
这段代码告诉我们CPython在内存中有如下事实
list类型的alist本身是一个Python对象,其对象实体就是在堆内存中。 list类型的对象,作为一个容器级别的对象,其列表存储的是元素实体的引用,而非元素实体本身。
对list对象中的某个元素的修改的本质是令被修改元素指向其他元素的引用,而我们修改该元素时,实际上CPython在堆内存中创建了一个新的对象(本例中的整数22)分配新的内存空间,并且保存该新增的对象(整数22)。alist的第三个元素不再对2的引用,更新为对22的引用。
list类型对象的在其元素修改前后,变量alist始终引用同一个list对象。
那么从上面的例子,我们得知:
**可变对象的实质:**其内部元素可修改是可变更对其他Python对象的引用。其可变对象的元素可以是数字、字符串,甚至可以是其他容器级别的可变对象。
不可变对象:就非常容易理解了,上面示例中list的元素对象都是不可变对象。推而广之,Python中的原始数据类型,例如数字类型(int,float)、字符串(str)、字节数组(bytes)。
在Python中,一切事物都是对象,不论是整数,字符串,甚至是其他容器级别的数据类型,都由CPython的C底层由一个叫struct PyObject结构体所封装。PyObject的结构体在CPython运行时存储在堆内中。
小结
我们从堆内存的角度理解,为什么CPython要对Python对象分为:可变对象和不可变对象,初衷是尽可能低简化堆内存的分配。因为Python变量持有Python对象的引用(或者从C底层去理解,持有PyObject对象的指针)去访问Python对象实体本身,比持有一个Python对象实体的副本更高效,更节省堆和栈的内存开销。
那么当多个Python变量引用同一个Python对象就涉及到概念就引用计数器,引用计数器属于内存垃圾回收的范畴,由引用计数又会牵涉到CPython一个致命的诟病,GIL:全局解释器锁,为什么多年来CPython不能去掉GIL,很大原因跟引用计数器有关。